Building AI-powered personal task tracker
Demo of the AI TODO app https://ivan-tolkunov--surukoto-run.modal.run/ (warning: the app could take up to 30s to boot up). All data is reset after 5 minuts of inactivity. Try telling it: “add every color of the rainbow”, then “mark all todos mentioning colors between green and violet as done” and “clean up completed todos”
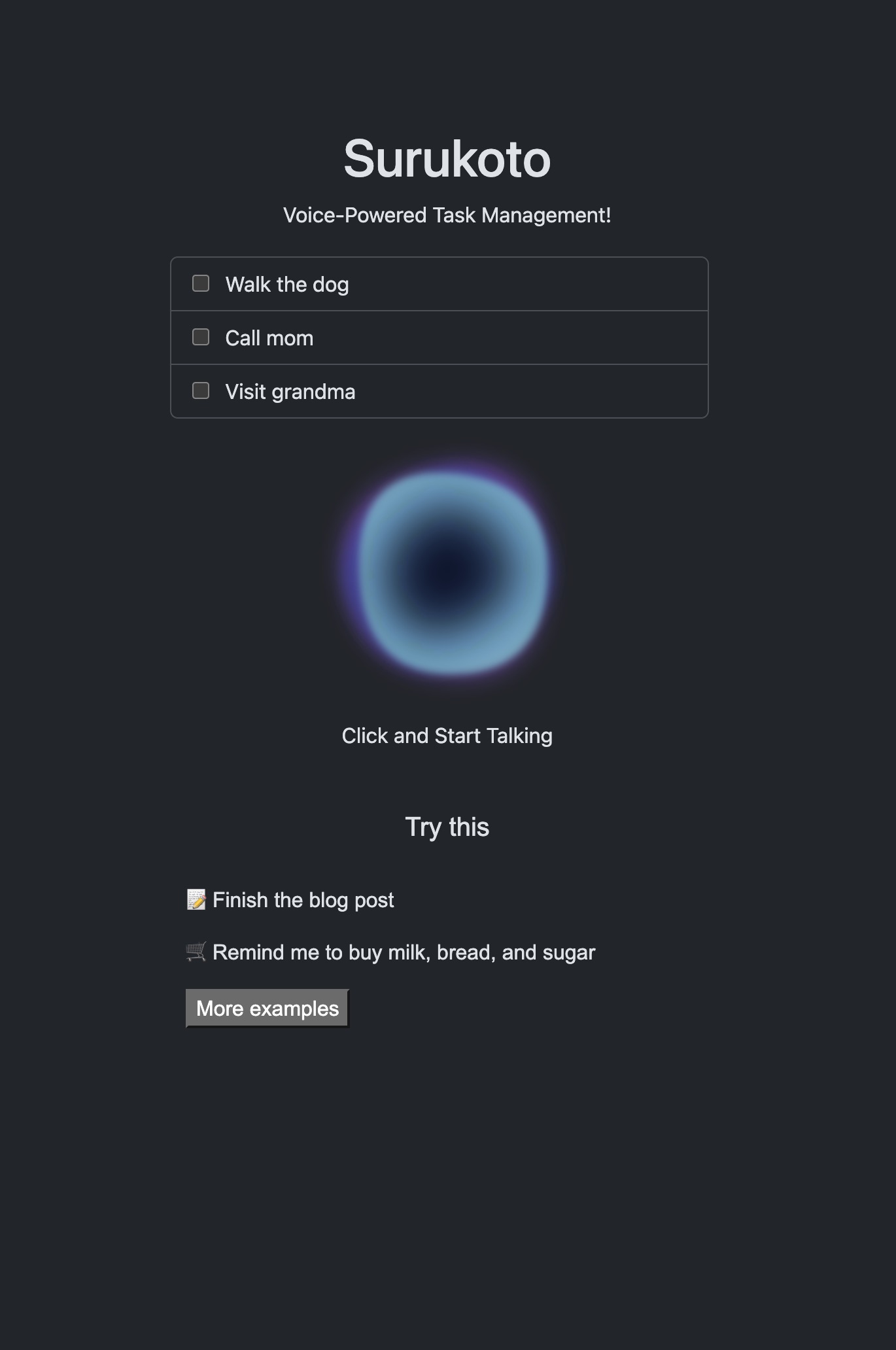
Everyone is building TODO apps to get started with a programming language or technology. I asked myself a question: what would a TODO app look like in the age of AI?
So I came up with an idea to build a TODO app you can simply speak to to give instructions. I started with a simple use-case of telling the app to “add milk to the shopping list”. But then I realized that using modern LLMs, I could also make the app check-off TODO items or remove them based on the user commands. The app turned out to be really fun to use!
Under the hood, it’s a simple Django web app. The model is very simple:
from django.db import models
class Todo(models.Model):
title = models.CharField(max_length=100)
created_at = models.DateTimeField('Created', auto_now_add=True)
update_at = models.DateTimeField('Updated', auto_now=True)
isCompleted = models.BooleanField(default=False)
def __str__(self):
return self.title
However, on the backend, instead of having a typical CRUD (create, read, update, delete) operations, I have a single endpoint that accepts a voice command:
from django.urls import path
from . import views
app_name='todos'
urlpatterns = [
path('', views.IndexView.as_view(), name='index'),
path('process-voice-command/', views.process_voice_command, name='process_voice_command'),
]
The endpoint is triggered from the frontend using simple HTML audio APIs:
const recordButton = document.getElementById("record");
const recordButtonText = document.getElementById("record-text");
let recorder = null;
recordButton.onclick = async () => {
if (recorder) {
recorder.stop();
recorder = null;
return;
}
const chunks = [];
const stream = await navigator.mediaDevices.getUserMedia({ audio: true });
recorder = new MediaRecorder(stream);
recorder.ondataavailable = (e) => chunks.push(e.data);
recorder.onstop = async () => {
const blob = new Blob(chunks, { type: "audio/webm;" });
const formData = new FormData();
formData.append("audio_file", blob, "voice-command.webm");
const response = await fetch("/todos/process-voice-command/", {
method: "POST",
body: formData,
});
window.location.reload();
};
recorder.start();
};
I’ve also added a cool animation to make it look like Apple’s Siri:
When the user submits their audio, I use Whisper to transcribe it (uses medium.en model as a good balance between size and its ability to understand my English):
def process_voice_command(request):
audio_file = request.FILES.get('audio_file', None)
file_name = default_storage.save(voice.name, voice)
try:
audio = whisper.load_audio(MEDIA_ROOT + file_name)
audio = whisper.pad_or_trim(audio)
result = self.model.transcribe(MEDIA_ROOT + file_name)
text = result["text"].strip()
Todo.objects.create(title=text)
finally:
default_storage.delete(file_name)
This was a great start! But I wanted to make this even smarter!
Using LLM to make TODO app do things
Instead of just saying what I want to do, I wanted to tell the TODO app to do things for me. E.g. when I bought milk, I wanted to tell the app: “I bought the milk” and have it check off the todo item for me.
To do that, I used a pre-trained LLM and some clever prompt engineering.
My initial plan was to run the LLM locally. However I was short on time because of Christmas holidays, so I’ve decided to use a hosted version for now. I definitely didn’t want to get locked in with OpenAI, so I found a powerful open source model (mixtral-8x7b-instruct) and used OpenRouter to query a hosted version.
The gist of the idea is this: I have a system prompt that explans to LLM that it’s being tasked with managing TODOs. As the output, I tell the model I expect a JSON-formatted list of instructions. The instructions can be add, complete, delete and error (when it’s not sure what to do).
First of all, I tested some prompts using OpenRouter chat UI. When I was happy with the prompt, I made a simple API call with the required data
def get_command(self, text):
response = requests.post(
url="https://openrouter.ai/api/v1/chat/completions",
headers= {
"Authorization" : f"Bearer {os.environ['OPENROUTER_KEY']}"
},
data=json.dumps({
"model": "mistralai/mixtral-8x7b-instruct",
"messages": [
{"role": "system", "content": self.prompt + self.todo_to_string()},
{"role": "user", "content": text},
]
})
)
print(response.json()["choices"][0]["message"]["content"])
return json.loads(response.json()["choices"][0]["message"]["content"])
Then, based on the response, I make it do things to the database:
def process_voice_command(request):
audio_file = request.FILES.get('audio_file', None)
text = util.get_voice_text(audio_file)
commands = util.get_command(text)
for command in commands:
action = command['action']
if action == "add":
util.add(command['text'])
elif action == "complete":
util.complete(command['task_id'])
elif action == "delete":
util.delete(command['task_id'])
elif action == "error":
messages.add_message(request, messages.ERROR, command['text'])
else:
print(f"Unknown action: {action}")
return JsonResponse({'success': True})
This is not perfect. The main issue is that it’s prone to prompt injection, i.e. the user can tell it to do things that it’s not supposed to do as part of their TODO text. Also I noticed it can even interpret the text of the TODO as part of the instruction, and things get very confusing.
But I was surprised with how well it all works!
I was able to give my TODO app commands like:
- add every color of the rainbow
- mark all todos mentioning colors between green and violet as done
- clean up completed todos
Now my TODO app has superpowers!
Similar to my other projects, I deployed the app to Modal.com for everyone to play with. It uses an in-container local SQLite database and 5 minutes container_idle_timeout, so the data gets reset after some time. Perfect for the demos!
In the future, to make the app more useful, I’m planning on several improvements:
- Make the voice command streamed to the server and transcribed in real time. This will show the user what the app is doing so there’s no surprises.
- A simple UNDO button that reverts the last thing AI did.
- Improve the prompting to avoid prompt injections and decrese the influence of the existing TODOs.
- Add accounts and store data in a hosted DB like Mongo or Postgres.
- Run the LLM inside the app container. I want to get deeper into AI and learn how things work under the hood.
Full source code is available at https://github.com/ivan-tolkunov/surukoto. Feel free to send Pull Requests!